In this section, we first give a quick overview of Natural Semantics, before explaining how we can apply it to Web sites.
Our goal in this section is not to give a complete description of
Natural Semantics, but to give a sufficient number of elements to show
how it can be applied to Web sites.
Natural Semantics [Kahn1987] has been developed to specify the
semantics of programming languages to allow mechanical manipulations
of programs and generation of compilers. It aims at two main goals:
providing an executable semantic specification formalism [Despeyroux1987] and
allowing proofs [Despeyroux1986].
Programs are structured documents that can be represented as
trees. The set of syntactical constraints that legal programs must
respect is called the abstract syntax of the programming language. If
we thought of an XML document as a tree, we can identify the notion of
abstract syntax with the notion of DTD, even if the expressiveness of
declaring an element is less powerful that giving the signature of an
abstract syntax operator (Abstract syntaxes traditionally define
operators and types, while only operators, called elements, are
defined in a DTD). In both cases these constraints are context free.
Natural Semantics has its origin in the structural operational
semantics developed by Plo81. Only the purely natural
deduction part of it has been retained, and the style of the
definition is closed to the natural deduction style, using Gentzen's
sequents [Szabo1969].
The natural semantics of a programming language or more generally of a
computer formalism is given by one (or more) formal systems (sets of
axioms and inference rules) which define sets of valid theorem
(theories). Basically, these inference rules express a way to
navigate in a program or in a document, checking that some properties
(called consequents) are true. But, in opposition to syntactical
constraints, these properties can most of the time only been checked
in a given environment that contains more information that in what is
generally called a context. In the case of the static semantics of a
programming language, this environment contains the so called symbol
table which contains the set of visible variables or objects together
with their types, while the dynamic semantics contains a memory state
that is a mapping from variable names to values. In this context,
performing a computation (as type-checking a program) is proving that a
particular predicate (this program is correctly typed) holds in the
theory. Natural Semantics is declarative and does not define the tactic
used to build proofs.
We try now to give a more precise idea of Natural Semantics, giving
some examples of rules.
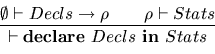
Natural Semantics has been implemented by means of a specification
formalism called Typol [Despeyroux1988]. It is part of a programming environment
generator called Centaur [Borras et al.1988] that allows the definition of the concrete and
abstract syntaxes of programming languages, pretty printing rules, and
semantic rules. The environment offers support for creating a good
man-machine interface. While most of the system is written in Lisp,
semantic rules (and possibly parsers and un-parsers) are translated
into Prolog code.
This implementation includes two features that are used to construct
real tools: an error recovery system that allows to specify special
rules that are used when an error occurs providing error messages, and
the ability to keep track of occurrences in the source tree and
to indicate precisely where errors occur.
Markup based languages are good candidates to specify their semantics
using Natural Semantics. An XML validator checking that an XML page
complies with a particular DTD is part of what can be generated with
Centaur if the static semantics of XML is specified in Typol.
However,
this is not exactly our goal as we want to give a semantic to Web
sites. In the following we are considering sites implemented in XML,
but the method can be easily extended to HTML. We can consider that
the real implementation language of a site is not XML but a language
defined by a set of XML tags. The usage of these tags can be
constrained by some syntactical rules: a DTD. To define completely the
language, we have now to find a way of defining semantic rules.
In our running examples, DTDs have been manually translated to AS
[Despeyroux1996], a Centaur formalism to define modular abstract syntaxes
(this should be quite easily performed automatically). This is
sufficient for Centaur to generate a syntactical editor for our sites.
The next step is to define the static semantics in Typol and to get advantage
of the Centaur interface to derive an executable version of this semantics.
Executable in this context means that, once we have compiled the semantic
rules,
we get a tool that can check that a particular site complies with the semantic
rules, providing
error messages or warnings if necessary.
In our vision, the role of the creator or the administrator of a
Web site is quite more important that the traditional web-master one
as it must take care of the semantics of the site.
We can here get the advantage of using an executable semantics:
from a specification we can produce such tools as validators, compilers
or debuggers.
We reach here the main distinction between checking a program, where
all concepts (types, numbers etc.) are very precisely defined in a
mathematical way, and checking a Web site where we manipulate natural
languages and some representation of knowledge that cannot be
manipulated by a theorem prover. Hopefully, the way Natural Semantics
is conceived and implemented makes it possible to delegate some parts of
the deductive process to external tools.
In the context
of a Web site, two parameters may evolve: the contents, and the
semantic constraints. In the last case, one have to regenerate the
compiler itself (i.e. the site validator)
before checking that the site is still correct. The
Centaur environment generates a generic debugger than can be used to
debug the semantics itself.
In this section we give two examples of Web site static specifications
that have been done with the help of Natural Semantics.
Specifying a Thematic Directory
A thematic directory is a way of classifying documents found on the
Web and presenting them to users in an organised manner. They can be
found as services provided by portails such as
Yahoo3
or Voilà4. Topics are
presented in a hierarchical manner as categories and sub-categories. Most
of the time, documents indexed in such a directory are selected
and classified manually. Such directories must evolve frequently, as new
documents are very often available and because it is some time helpful
to reorganise the hierarchy of categories. After each modification in
such a directory, one would like to check the integrity of it.
The whole directory is a tree that contains two different types of
node. The first type of nodes concerns categories that come with a
list of sub-categories. For example the category Travel may
contains the sub-categories Boating, Backpacking, etc. In this case, one want
to check that sub-categories make sense in the context of the upper
level category, by reference to a thesaurus or an ontology. The
second type of nodes concerns leaf categories that come
with a list of documents, or more exactly with a list of descriptions
and links to documents. In the hypothesis in which a list of keywords
is provided for each document, one would like to check that this list
is relevant in the context in which the document is referred. The
structure of the site (what we call its abstract syntax) can be
described as a DTD while the site itself is an XML document.
To specify the coherence of such a site, one will affect a type to each
node. A node has a type if and only if all subtrees are typed. Type
expressions are made of a list of names that should appear in the thesaurus.
Sub-categories must get a type that is "more precise" that the
type of the upper
category. For example, it is possible to say that the type Travel.Boating
is more precise than the
type Travel because it makes sense to speak of Boating in the
context of Travel according to our favourite thesaurus.
The two following rules are equivalent
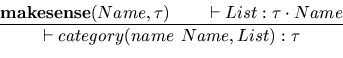
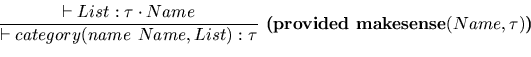
The expression category(name Name, List) uses the Typol syntax to describe a schema in which Name and List are variables. It matches pieces of XML text (or tree) like the following one:
<category> <name>...</name> ... </category>
A category appears in a context in which some category nodes have
already been traversed (except for the top ones for which the context
is empty). The predicate makesense is an external predicate
that may call a thesaurus (or a ontology) browser to verify that the
relation between categories and sub-categories is respected. The order
of premises in the upper part of the rules is not theoretically
important. All premises must be proved to allow the inference. When
a premise can be viewed as a test or a function call, the second form
may be preferred. The second form makes clear that it is a conditional
recursive rule.
A reference may be affected the type ![]() if it contains a sufficient
number of keywords that make sense for this type. We can call this a confidence
degree.
if it contains a sufficient
number of keywords that make sense for this type. We can call this a confidence
degree.
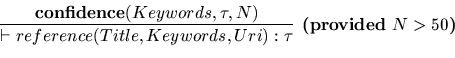
In this rule, we can use again an external predicate that calculates a
rating number that must say what percentage of the list of keywords
is relevant in the current context (category). It is the choice of
the web-master to impose this ratio.
In the above rules, we have chosen to call an external predicate that
is viewed as an axiom from the theory defined by the rules. It should be
possible to define the thesaurus as a term, defining also access
procedures to the thesaurus in Typol. In this case, the thesaurus
should be considered as a parameter (an hypothesis) in the rules, and the sequents should have the form
![]() ,
saying that X has type
,
saying that X has type ![]() in the context of a particular thesaurus
in the context of a particular thesaurus ![]() .
.
When the proof that, according to the specification, the Web site is
correct cannot be constructed, some recovery rules are used to provide
error messages or warning.
Specifying the Coherence of an Institutional Site
Verifying an institutional site as a research institute one is
closer to type-checking a program than the previous example. The
hypothesises are the following: an authority, may be the staff, is in
charge of the general Web site presentation that is the official view of the
institution; then some subparts of the site are edited by other groups
of persons, may be some researchers in charge of a particular project.
We can see this form of site as containing a declarative part, and an
other one than must follow these declarations, even when the first
"declarative" part is updated. For example, each team may produce a
list of other teams with which they cooperate.
In the following figure, the inner box must be considered as a page
accessible by the link A.

As some teams may
disappear, it is reasonable to check that a particular team does
not pretend having some collaboration with a team that does not
exist any more.
We are facing the usual problem of forward declarations in programming
languages: each team-page must be checked in an environment
containing the list of all teams. Three possibilities are available
using natural semantics: the more operational one consists of a
two-passes process (one to construct a list of teams, a second to check the
team pages), a second possibility consists in constructing a fix
point, a third one consists of considering the whole site as a context
as shown in the following rules.
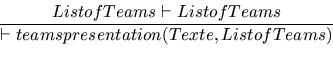
Each time a reference to a team exists, we must check that it is in the legal list:
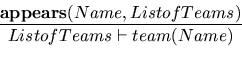
This approach supposes that references to teams of the institute are correctly tagged in the document.